

by Julius Donnert
Over the last few weeks, the LOFAR collaboration dropped a bunch (20+) new papers on ArXiv - we wanted the data, now we’ve got them. This was part of the initial data release of the LOFAR Two Meter Sky survey. It is worth taking a closer look at a few of these new observations related to diffuse cluster emission. The images are spectacular and unveil the complexity of extra-galactic radio emission - a field that once was a niche in astronomy.
Before you click your way through the gallery of observations, let’s appreciate that every single image was reduced from >17 TB of complex radio data by a PhD student in Leiden, Bologna or Hamburg. Radio astronomy has a steep learning curve, this is rocket science ...
So thank you to the students for the hard work and the frustration that it takes to gnaw on the data until the noise level is micro Jansky, the bright sources clean beautifully and the flux scale is accurate to a few percent. This his hard …
This is a fantastic new glimpse into the faint radio sky at 150 MHz. Click on the image to go to ADS and read the paper.
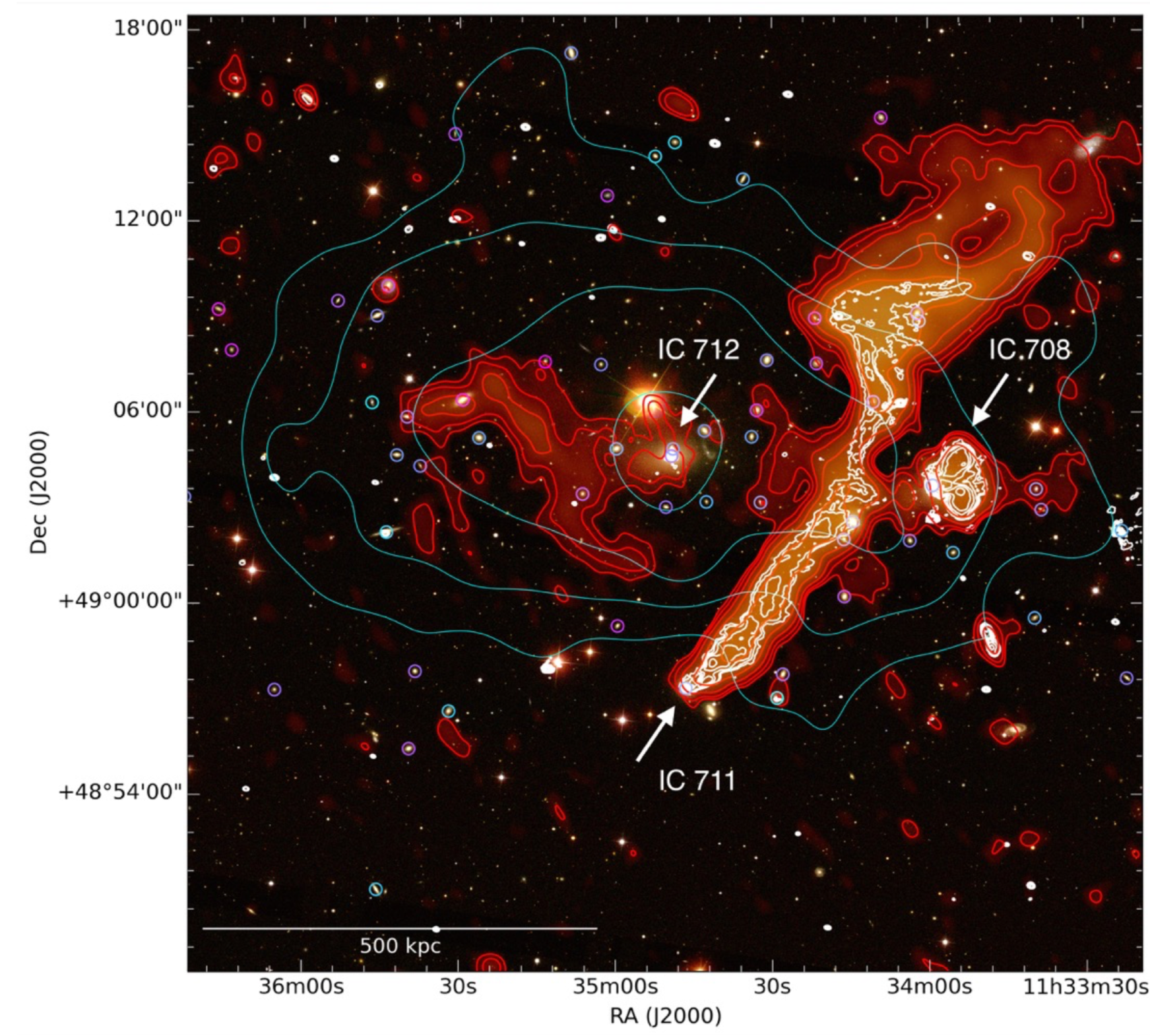
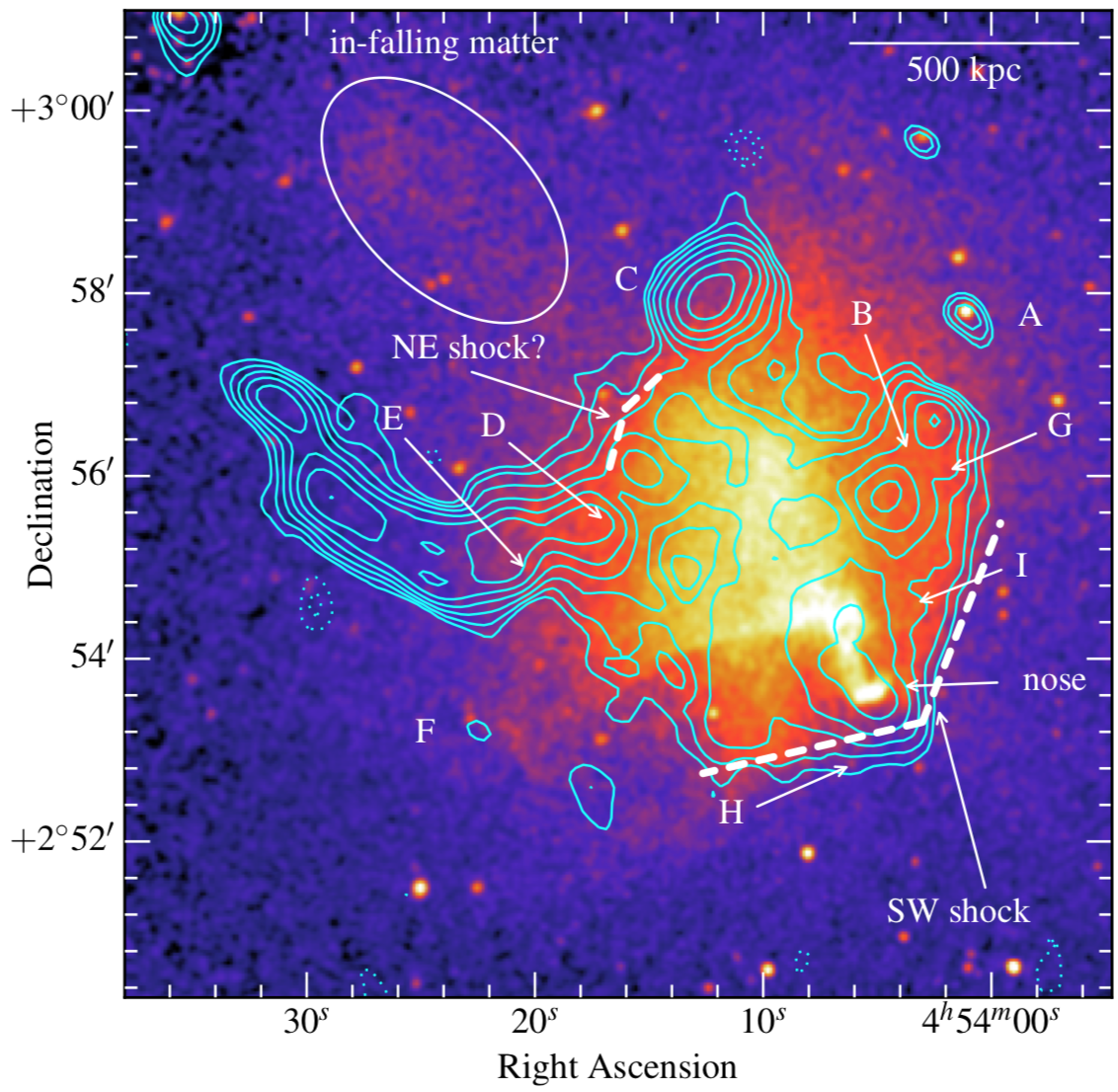
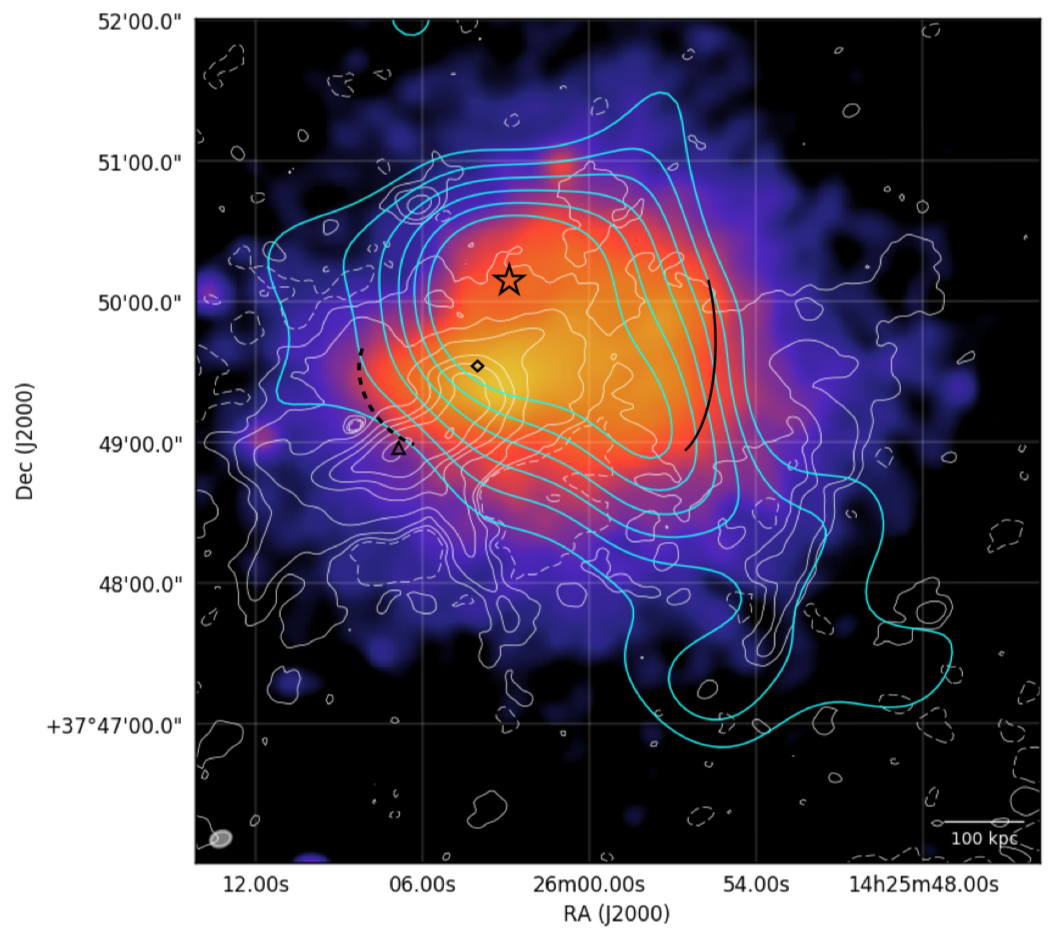
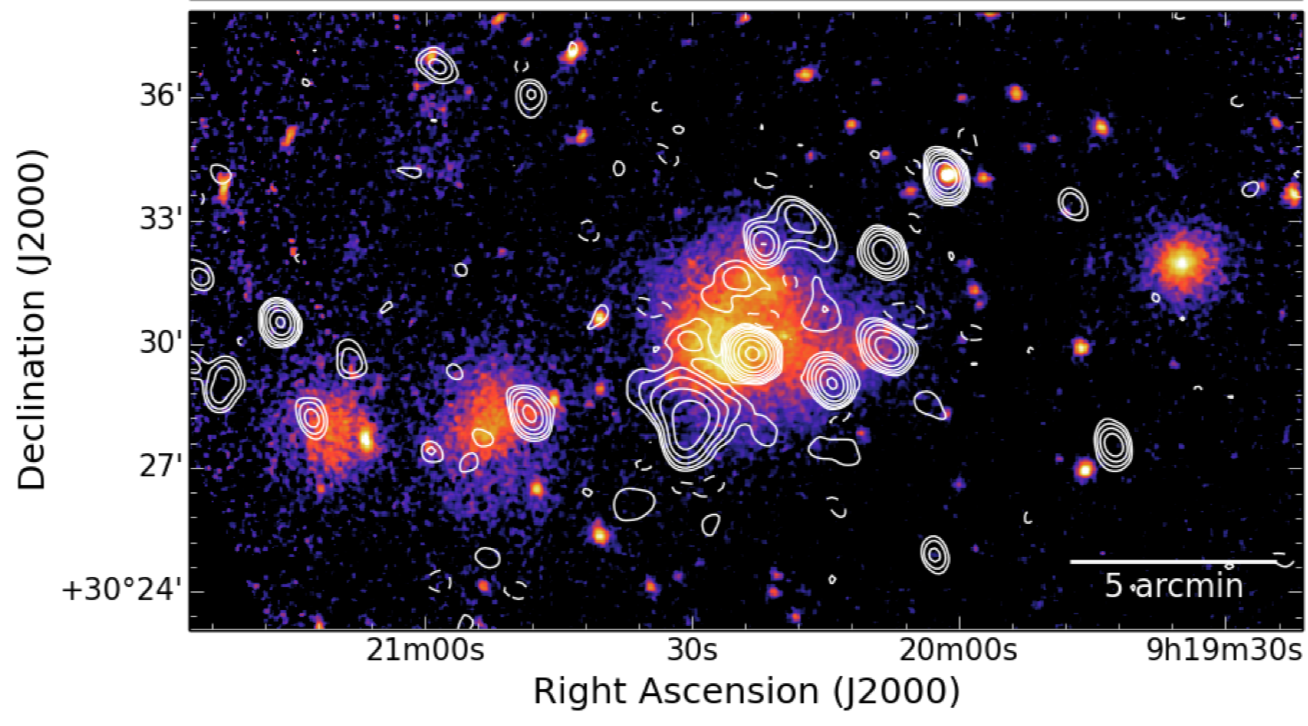
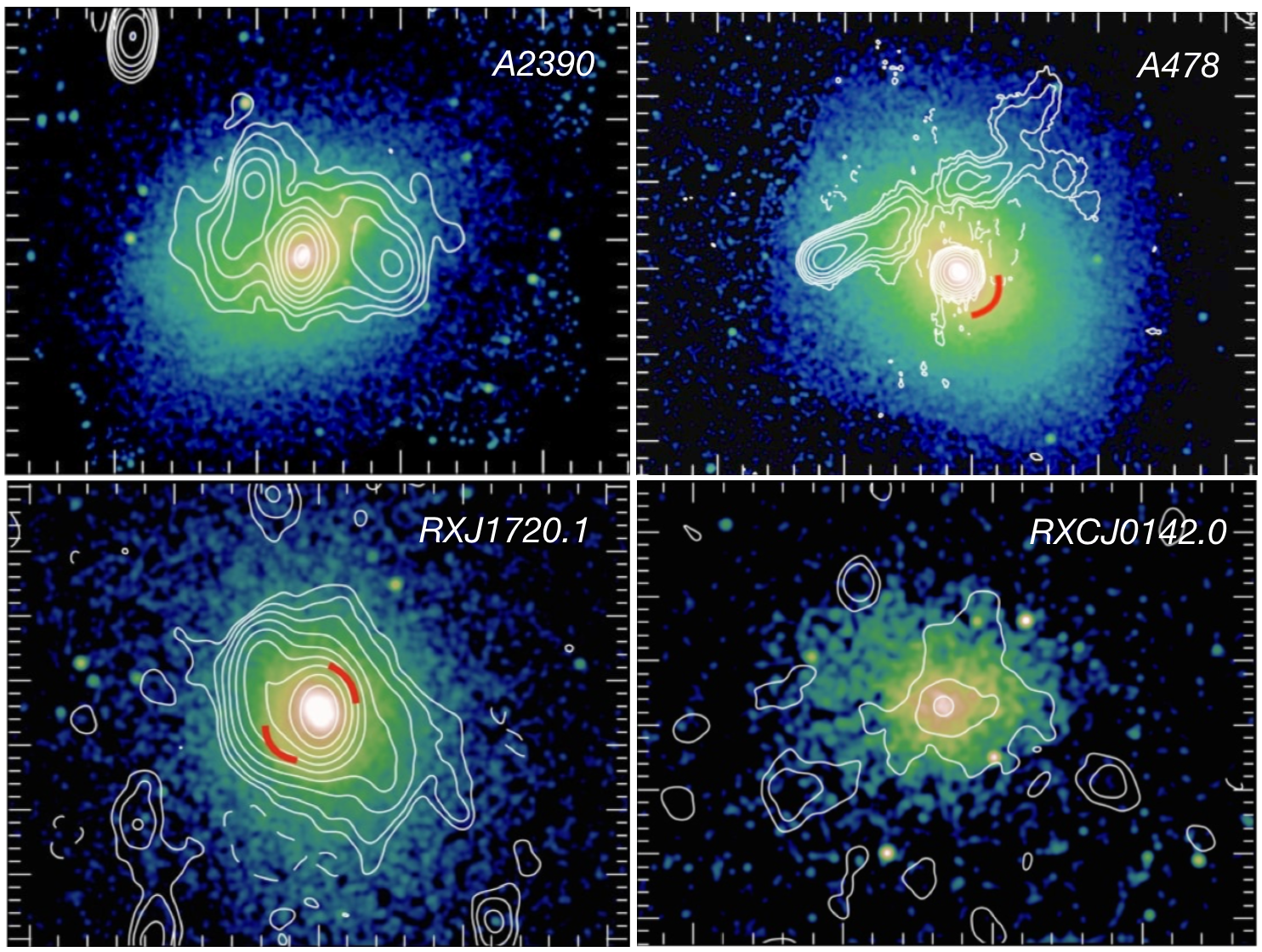
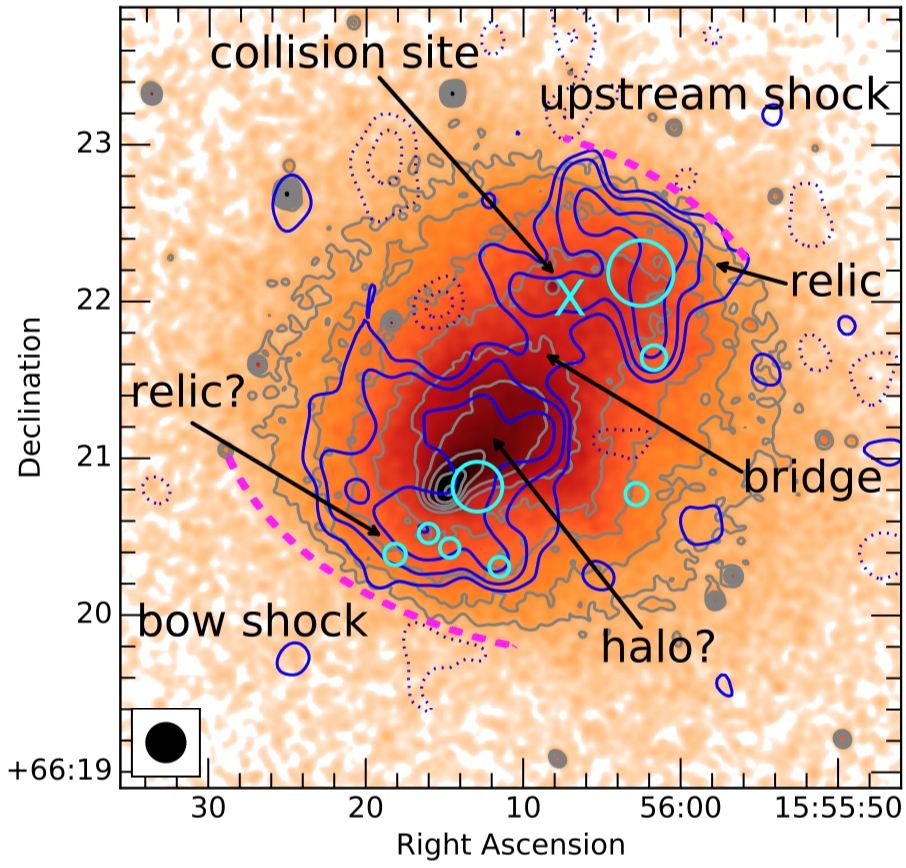
Of course many other papers were part of the LOFAR splash, some of them very technical, other focussing on radio galaxies (some of them always active), quasars, AGN, blazars, recombination lines, famous fields, redshifts, optical counterparts, reionization and higher radio frequency follow-ups with the Indian GMRT - pick your favorite ! The instrument pipeline especially of the LBA (70MHz) is still under heavy development, so the data quality will become even better in the next years.
As a final remark, let’s remember that the first LOTSS data release covers only ~5 percent of the northern sky, so we will see some amazing science in the next years. Stay tuned !
Current sky coverage of the LOTSS (Shimwell et al 2018). Green is published, red is observed, yellow is scheduled, black is unobserved.
